The Reliability Gap in AI Essay Grading
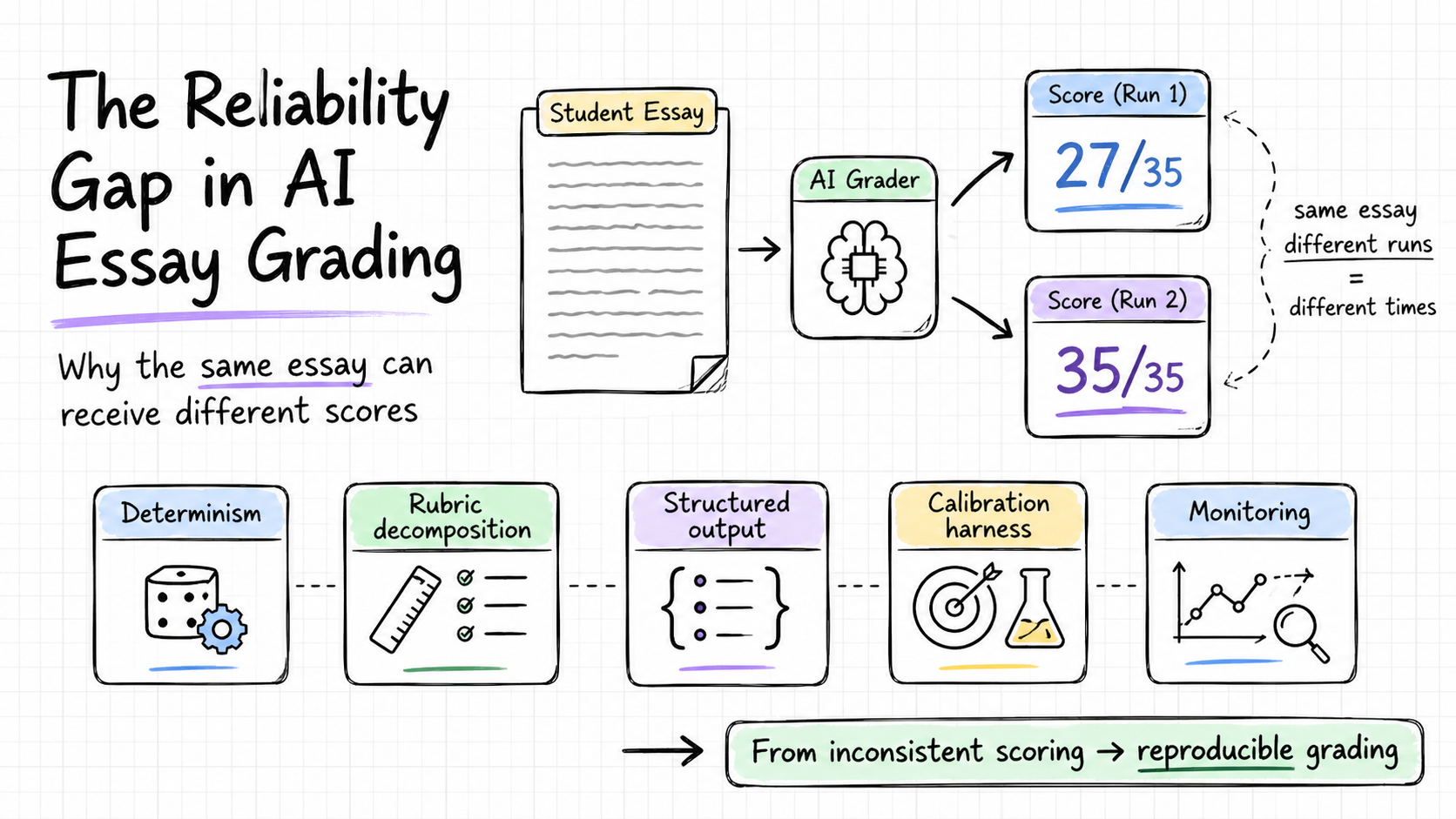
- The failure. AI essay graders give different scores to the same essay on different runs. The Medly AI review documented scores swinging from 27/35 to 35/35 with no input change; ChatGPT-as-grader has been reported at up to 60% run-to-run variance. Off-topic essays, including the Queen's Christmas Message, score high regardless.
- The cost is real. In autumn 2025, Massachusetts had to rescore around 1,400 MCAS essays across 192 districts after an AI grader systematically mis-scored student writing, inside a $150.8M state testing contract.
- It's a system problem, not a model problem. LLMs are inherently non-deterministic; making them reliable as a scoring instrument requires deliberate engineering at the system layer.
- Five controls turn an LLM call into a measurement instrument: determinism, rubric decomposition with self-consistency, structured output, calibration & adversarial testing, and production monitoring.
- Right-size the investment. Formative tools (advisory feedback only, scores stay out of the gradebook) at small scale should ship the cheap wins (Controls 1 + 3). Summative scoring (counts toward grades, transcripts, or official records) needs the calibration harness before launch. Enterprise summative builds all five, plus a human audit layer.
This is the first post in Failure Modes, a series that takes an AI product or suite of products on the market, looks at the public failures that have emerged and their business consequences, and works through the technical design issues that produced them. Those issues are usually rooted in system design: choices around reliability, robustness, and whether the behavior the model produces matches what the use case actually requires. The case study below is about LLM-based essay grading. It shows how reliability and reproducibility have to be built into a scoring system deliberately, and what the engineering gap looks like in practice.
How did AI essay grading become a product category, and where did it break?
The release of ChatGPT in late 2022, and the capable language models that followed, demonstrated that these tools had crossed a quality threshold for complex language tasks. One use case emerged almost immediately as an obvious target: grading open-ended student responses. Multiple choice and fill-in-the-blank questions were already automatable. The hard problem had always been the constructed response, the essay, the short answer, the paragraph that a teacher has to read, annotate, and score against a rubric. That is where instructional time goes. A class of thirty students writing a 500-word response means 15,000 words to evaluate before anyone can move on.
Language models made this tractable for the first time at scale. Entrepreneurs moved quickly. Tools started appearing across exam preparation platforms, language learning apps, learning management systems (the software schools use to manage coursework and assignments, such as Google Classroom and Canvas), and dedicated teacher productivity software. Products like EssayGrader, CoGrader, and AutoMark took the same basic approach: ingest a teacher's rubric, read a student essay, and return a score with rubric-aligned feedback.
The adoption data reflects genuine product-market fit. EssayGrader claims 100,000 teachers at over 1,000 schools. A Gallup-Walton Family Foundation poll found that AI-using teachers apply it across a range of classroom tasks (preparing materials, drafting feedback, and grading among them), with weekly users saving 5.9 hours a week, the equivalent of about six weeks per school year. One analyst estimate (Business Research Insights) values the automated essay scoring software market at around $310 million in 2025 with several-fold growth projected by the early 2030s; other reports give different numbers, so the precise figure should be read as one estimate rather than consensus. The directional point is the easier one to defend: this is one of the cleaner AI use cases of the current wave, with real, painful demand and visible adoption.
The category had built real momentum by the time the reliability failures started becoming visible in 2025. A public investigation of the UK study app Medly AI, originated by the YouTube channel 1st Class Maths and re-reported in November 2025 by SHLC Tutors, documented the same essay scoring "anywhere from 27/35 to 35/35 depending on when it was submitted," with no rubric or input change between runs. As part of the same investigation, the Queen's Christmas Message reportedly received a score of 40 out of 40 when submitted as an essay response, an extreme illustration of off-topic robustness failure rather than a formal audit, but consistent with the broader pattern. A teacher quoted in the review described the experience as "clunky and at times inaccurate." Separately, MarkInMinutes (a UK marking service whose own product competes with using ChatGPT directly) reported in its own testing score variance of up to 60 percent on identical submissions; that is vendor-blog evidence, not third-party benchmarking, but it points the same direction. Academic research on LLM-based scoring has documented the same instability pattern under controlled conditions.
"Anywhere from 27/35 to 35/35 depending on when it was submitted." Same essay, no rubric or input change between runs.
The most consequential failure came at the institutional level. In autumn 2025, the Massachusetts Department of Elementary and Secondary Education had to rescore around 1,400 MCAS essays across nearly 200 school districts (Boston.com's initial reporting cited 145; later public-records counts put the figure at 192) after the AI grader systematically mis-scored student writing, including at least one student who received a zero on an essay that should have scored 6 out of 7. The state acknowledged the error publicly, rescored every affected essay with human reviewers before releasing scores, and asked its testing vendor to implement guardrails before the next cycle.
The commercial challenge these incidents reveal runs across the entire category. Accuracy and consistency are what these products are sold on. The bar is reproducibility: the same essay, graded under the same conditions, should produce the same score within a stated tolerance. That bar requires deliberate engineering, and the incidents above show what happens when it is treated as a given. In low-stakes practice settings, users absorb the inconsistency. In high-stakes assessment, it surfaces as a concrete failure, with rescoring, public accountability, and contract risk to match. For a product category built on the promise of reliable automated grading, that is a foundational problem to solve.
LLM graders as measurement instruments
To understand why these failures happen, it helps to look at how these tools are built. What follows is a working hypothesis based on how this category generally operates and what the engineering literature says about LLM-based scoring.
A typical AI grading tool connects a teacher's interface to a hosted language model. The teacher provides a rubric and a student essay. The tool assembles a prompt from those two inputs, sends it to a large language model from a provider such as OpenAI, Anthropic, or Google, and parses the response to extract a score and feedback. That is the core loop, and for many of these products, it is essentially all there is.
The key property to understand about large language models is that they are inherently non-deterministic. Send the same prompt twice, and you will often get two different responses. This is called stochastic decoding: the model generates text by sampling from a probability distribution over possible next tokens at each step, rather than always picking the most probable one. For creative applications, that variability is a feature. Applied to scoring, it creates a reliability problem.
Most LLM providers offer parameters to control this. Temperature is one of them: setting it to zero biases the model toward the most probable next token at each step, sharply reducing (though not eliminating) run-to-run variation. Version pinning matters equally: LLM providers release updated versions of their models regularly, and a product locked to a specific version will produce consistent outputs over time, while one running against the latest version will drift as the underlying model changes. A grading tool running at default temperature settings without version pinning will produce different scores for the same essay on different runs. That is the most direct explanation for the score variance in the Medly AI review and the 60 percent run-to-run variation reported when ChatGPT is used directly as a grader.
There is a second failure mode, separate from run-to-run variance: some of these tools assign high scores to essays that are entirely off-topic. The case where the Medly AI review found the Queen's Christmas Message receiving a perfect score reflects a pattern with a longer history than LLMs. Les Perelman, the former director of writing across the curriculum at MIT, built a tool called the BABEL Generator that produces grammatically fluent, academically styled text that carries no coherent meaning. Submitted to automated essay graders over many years, it consistently received high scores. Perelman's summary of the finding, reported in Vice in 2019: "The BABEL Generator proved you can have complete incoherence, meaning one sentence had nothing to do with another, and still receive a high mark." A 2024 paper studying modern automated essay scoring systems found the problem persists: these systems score well-formed text highly regardless of whether it addresses the prompt.
"You can have complete incoherence, meaning one sentence had nothing to do with another, and still receive a high mark." (Les Perelman, MIT)
The fields of trustworthy AI and responsible AI have specific names for what is missing. Reproducibility is the property that the same essay, graded under the same conditions, produces the same score within a stated tolerance. Robustness is the property that the system performs correctly across the full range of inputs it will encounter in practice, including off-topic and adversarial ones. Validity is the property that the system actually measures what it claims to measure: that a high score reflects genuine writing quality. These three properties are distinct, and a system can satisfy one while failing another. A grading tool can be perfectly consistent and still score the wrong thing. It can score the right criteria and still be gamed by a student who figures out what the model rewards. The NIST AI Risk Management Framework treats "Valid and Reliable" as the foundational characteristic of any trustworthy AI system. For a grading product, all three have to be engineered in deliberately.
Three properties of a trustworthy grader
A system can satisfy any one of these while failing the others, which is why each needs its own engineering control.
I'd argue the most useful reframing here is about the system, not the model. An LLM's non-determinism is a core property of how it works, and it has to be managed at the system level. The system (the parameter settings, the prompt engineering, the evaluation infrastructure, the validation logic) is what determines whether the model's outputs become reliable, robust, and valid as a grading instrument. A tool that passes a rubric and an essay to an LLM and returns whatever comes back has delegated all of that responsibility to the model. The model is a generative tool; it is the system around it that must enforce the properties a measurement instrument requires.
From an LLM call to a measurement instrument
What follows are five engineering controls that, taken together, address the reliability gaps described above. They are ordered roughly from simplest to implement to most involved, and they target different failure modes: run-to-run variance, output parsing errors, off-topic and adversarial inputs, calibration drift, and production monitoring.
Control 1: Determinism. The first and simplest change is setting the model's temperature parameter to zero, fixing the seed where the provider exposes one, and pinning the product to a specific, named version of the model. Temperature controls how much randomness the model uses when generating a response. At zero, it biases the model toward the most probable next token at each step, producing much more consistent outputs across repeated calls. Version pinning ensures the model the system was built and tested against is the model users are scored by; most LLM providers release updated versions regularly, and a product running against the latest version will change behavior as the underlying model changes. OpenAI's documentation and Azure's guidance cover the implementation. Together, these changes close the large majority of run-to-run variance. They do not produce strict bit-for-bit determinism; hosted LLM APIs are mostly deterministic, not strictly so, because batching, mixture-of-experts routing, and floating-point ordering all introduce small residuals. For high-stakes scoring, idempotent score caching and regression tests against a fixed essay set catch what these settings leave behind.
Control 2: Rubric decomposition and self-consistency aggregation. A single LLM call that grades an entire essay holistically introduces more variability than one that scores each rubric criterion separately. The more reliable approach is to break the rubric into individual criteria, score each one in a dedicated call, and then run that call multiple times (five to ten is a reasonable starting point), taking the median or majority score across the runs. This technique is called self-consistency aggregation: if five independent calls agree on a score for a criterion, that score is more trustworthy than any single call. Wang et al. showed that aggregating over multiple samples reliably reduces variance and converts run-to-run noise into a measurable confidence estimate, in the context of chain-of-thought reasoning tasks. Taubenfeld et al. refined this further, cutting the number of calls needed by about 40 percent by weighting samples according to the model's own confidence in each response. Both results come from general LLM reasoning research rather than essay grading specifically; the technique is plausible as a reliability control for rubric scoring but should be validated on the grading product's own calibration set before its variance reduction can be claimed quantitatively. Hamel Husain, drawing on more than 30 engagements with companies building LLM-based evaluators, makes a related point about evaluator design: binary pass/fail judgments per criterion are often clearer than numeric Likert scales, because adjacent numeric labels are subjective and inconsistent. That logic applies to the internal evaluator that drives self-consistency aggregation; the final student-facing score can still be numeric.
Control 3: Structured output. When a model's response is free-form text that the system then parses to extract a score, two things can go wrong: the parsing can fail when the model uses unexpected phrasing, and small variations in how the model words its response can produce different extracted scores even when the underlying assessment was the same. The solution is to require the model to return a structured response tied directly to the rubric: one field per criterion, a fixed set of allowed score values, and a required reasoning field. This is called constrained decoding or structured output, and most major LLM providers support it through function-calling or JSON-mode APIs. For teams building this in code, open-source libraries handle the schema enforcement automatically. Outlines compiles the schema into a finite-state machine that guides token generation directly, guaranteeing valid output on every call. Instructor, built on Pydantic (a widely used Python data validation library), provides a simpler interface for teams working with hosted APIs. The thing to be clear-eyed about: structured output guarantees shape, not truth. A valid JSON object can still contain a bad score. This control prevents parsing errors and keeps downstream code from breaking; it does nothing for assessment validity on its own.
Control 4: Calibration and adversarial testing. The first three controls address variance and output reliability. Testing whether the scoring is actually calibrated and robust to unusual inputs requires a dedicated evaluation harness: a maintained set of essays with known, human-verified scores that the system is tested against on a regular cadence. A useful harness covers the full score range, includes off-topic essays and adversarially constructed inputs (such as fluent text that addresses a different prompt entirely), and tracks agreement with human raters using standard metrics like intra-class correlation and quadratic weighted kappa. Any change to the model or prompts gets validated against the harness, and changes that degrade performance below a set threshold are held back. Shankar et al.'s EvalGen formalizes the process of building and maintaining this kind of evaluation set, and is candid about the ongoing cost of keeping it current as the product evolves. Score-scale design also matters; some general LLM-as-judge research suggests narrower scales (such as 0 to 5) align better with human raters than broader ones, but the right scale for any given product depends on its rubric and population. Teams should empirically test scale variants on their own essays rather than treat any single published result as portable.
Quadratic Weighted Kappa (QWK)
Click an AI score to change it. Watch how a 2-point miss hurts QWK roughly four times more than a 1-point miss, and a 3-point miss nine times more.
QWK
1.00
Strong agreement
1.00 = perfect
~0.00 = chance level
<0 = systematic disagreement
Real essay-grading studies typically use 100 to 1,000+ essays so QWK is statistically stable. With only 10, small changes can swing the score visibly. That's the lesson: QWK is a calibration metric for a corpus, not an individual scorecard.
Click any AI score to set it, or try a preset. Notice how a single 3-point miss damages QWK more than three 1-point misses combined; that's the quadratic part. The presets give a feel for the typical bands: perfect alignment at 1.00, mostly-within-one in the strong-agreement range, and random scoring near zero.
Control 5: Production monitoring and selective human review. For consumer-scale AI grading products, blanket real-time human review of every score is economically impractical. A product serving thousands of concurrent users cannot realistically route each submission to a qualified human reviewer, and the subject-matter expertise required to grade across different rubrics makes that kind of review layer genuinely hard to staff. The practical version of this control is targeted rather than blanket: flag scores where the model's confidence variance across multiple calls exceeds a threshold, and route those specific cases for human review. In parallel, maintain a production monitoring layer that tracks score distributions over time and alerts the team when behavior shifts, using an observability tool such as Arize Phoenix or Langfuse to catch drift before it compounds into a public incident. For high-stakes deployments (state assessments, credentialing decisions, placement exams), a more comprehensive human audit layer is appropriate, and the contract economics at that level support it. For consumer-scale practice and feedback tools, the stronger investment is in Controls 1 through 4, with monitoring as the safety net.
Running all five controls together addresses reliability at each layer of the architecture. Determinism settings and structured output reduce variance at the model call level. Self-consistency aggregation converts remaining uncertainty into a measurable confidence signal per criterion. The evaluation harness validates calibration and catches robustness issues before changes reach users. Production monitoring surfaces drift before it turns into a public incident. A grading system with all five in place produces scores that are consistent, auditable, and resilient to the kinds of inputs that have caused failures in this category.
How much should this cost?
The controls described in this article are drawn from responsible AI and trustworthy AI research. The goal in applying them is commercial. A team that invests in reliable scoring infrastructure should expect a return in contract security, reduced churn, or competitive advantage. This section works through what that return looks like and how to think about the investment in proportion to the product's stage and scale.
The build cost. One way to ballpark the investment is to estimate the engineering work required for each control. Control 1 (determinism settings) might take a day or two, or longer depending on how the product's infrastructure is organized. Controls 2 and 3 (self-consistency aggregation and structured output) together might take 3 to 5 weeks of focused engineering work. Control 4 (the evaluation harness) is the most substantial investment: several weeks of engineering plus a few thousand dollars to commission a set of human-rated essays. Control 5 (monitoring) adds another 2 to 3 weeks. At senior ML engineer rates somewhere between $150 and $200 per hour, that puts the rough total one-time cost somewhere between $80,000 and $150,000, with ongoing maintenance of $15,000 to $40,000 per year. These numbers are illustrative. The actual cost varies considerably with team structure, existing tooling, and implementation choices, and individual components could go faster or slower than this estimate suggests. The value of the exercise is in the order of magnitude, not the specific figures.
The inference cost. Self-consistency aggregation (Control 2) is the most significant ongoing cost driver. A 5-criterion rubric scored with 5 votes per criterion creates 25 model calls per essay; lighter configurations like 3 criteria × 5 votes, or 5 criteria × 3 votes, come in at 15. On Claude Sonnet 4.6 ($3 input / $15 output per million tokens) or GPT-5.4 ($2.50 input / $15 output per million tokens), a single baseline call costs around $0.007 to $0.008 per essay assuming roughly 1,200 input tokens (rubric plus essay plus system prompt) and 300 output tokens. At standard pricing, 15 to 25 calls put cost-per-essay in the $0.11 to $0.20 range. Prompt caching of the repeated rubric tokens, plus the 50 percent batch discount most major providers offer for non-real-time processing, bring this back down to roughly $0.05 to $0.10. Using a lighter model like Claude Haiku 4.5 ($1 input / $5 output) brings the same approach down to $0.015 to $0.030 per essay even at standard pricing. A product that routes most essays through the lighter model and escalates only uncertain cases to the flagship can realistically land at $0.02 to $0.04 per essay with all controls active. For a product priced at $7 to $15 per teacher per month, with a teacher grading around 100 essays per month, that inference cost is a real line item, roughly 20 to 40 percent of per-teacher revenue at standard model pricing, but it is manageable and improves as the product scales.
Cost Calculator
$3.00 input · $15.00 output / 1M tokens
1 = single holistic call · 5 = lightweight consistency mode · 15 = 3×5 or 5×3 · 25 = full rubric-decomposed self-consistency (5 criteria × 5 votes)
Cost / essay
$0.032
Cost / teacher / month
$3.15
% of subscription revenue
31.5%
Assumes ~1,200 input tokens (rubric + essay + system prompt) and ~300 output tokens per call. Prompt-caching discount averaged across cache reads and writes; production costs vary with rubric length, essay length, and provider rate cards.
Estimate inference cost per essay across model choice, call count, and pricing. Defaults reflect a teacher grading 100 essays a month at $10 per seat on Claude Sonnet 4.6 with prompt caching, landing inside the 20 to 40% of revenue band the prose describes. Switch to Haiku 4.5 to see the lighter-model economics; crank the calls slider to see how self-consistency aggregation changes the bill.
The platform opportunity. Before scoping a full custom build, it is worth checking what existing platforms and services already provide. Evaluation harness tooling is available in Braintrust, Confident AI, and similar products. Production monitoring is covered by Arize Phoenix and Langfuse, both of which have free tiers. Open-source libraries like Outlines and Instructor handle schema enforcement for structured output. A team that assembles the right toolchain, rather than building each component independently, can reach a production-grade implementation at a fraction of the custom-build cost. There is also a category-level opportunity in this space. The reliability infrastructure these controls require is largely the same across any rubric-based scoring product. An AI grading platform that packages these controls as shared infrastructure, rather than leaving each product team to implement them independently, would have a meaningful product differentiation argument alongside real cost savings for its customers.
The cost of a reliability failure. The Massachusetts MCAS rescoring of around 1,400 essays happened inside a five-year, $150.8 million state testing contract, roughly $30 million per year. A repeated incident at that scale is plausibly contract-ending. Against an $80,000 to $150,000 build cost, the economics of investing in reliability controls at that contract level are clear. The reputational risk matters for consumer products too. The Medly AI reliability failures were independently investigated and reported across tutoring blogs and YouTube channels, generating sustained negative coverage. On a base of 100,000 teachers at $7 to $15 per month, even modest churn driven by reliability concerns represents hundreds of thousands of dollars in lost annual recurring revenue. Reliability is a commercial asset, and the gap between what these products promise and what they currently deliver is the liability.
The formative feedback case. Products that provide informal, advisory feedback on student drafts (where scores stay within the tool and never enter a gradebook, transcript, or official record) face a different risk profile. In those contexts, an inconsistent score is an inconvenience rather than a consequential error. The student receives imperfect feedback, notices the inconsistency, and moves on. For those products, Controls 1 and 3 (determinism and structured output) are worth implementing immediately, because the engineering cost is negligible and the consistency improvement is real. Control 2's self-consistency aggregation adds inference cost without proportional benefit when the feedback is advisory and the stakes are low. Controls 4 and 5 can be deferred until the product moves toward graded or summative use cases, at which point the evaluation harness becomes a prerequisite rather than an enhancement.
Competitive positioning. These controls have commercial value independent of any regulatory requirement. A product that can demonstrate consistent, auditable scoring on the same essay competes on a dimension its category currently overlooks. That matters to procurement teams at school districts and testing organizations, who carry accountability for the scores their students receive. The question shifts from "how good is the AI?" to "how do you know?", and the controls above are what allow a team to answer that with evidence. If jurisdictions move toward requiring transparency in AI-assisted assessment, as the fairness implications of automated scoring make plausible, the same evaluation harnesses, audit trails, and monitoring layers that improve commercial competitiveness today will satisfy those requirements. A team that has already built them arrives at that conversation ready.
The question shifts from "how good is the AI?" to "how do you know?"
The practical sequence for a team deciding how much to invest: Controls 1 and 3 cost almost nothing and should be in place from the start. Control 4 (the evaluation harness) should come before any move toward summative or high-stakes scoring, because it is the only way to verify the system is calibrated. Control 2's self-consistency aggregation adds the most inference cost and can be prioritized once the product generates enough margin to support it. Control 5's monitoring layer belongs in any product that is live and serving real users.
Which controls should I implement?
Determinism
Self-consistency
Structured output
Calibration
Monitoring
Recommendation
Low stakes, low scale. Ship the free wins now and revisit when you move toward summative use or hit mid-market scale.
Pick the stakes and scale that match your product to see which subset of the five controls the article would prescribe, and which to defer until the use case shifts.
The same dynamic appears in every domain where an LLM stands in for a measurement instrument. Essay grading is just the version where the gap between expected and actual behavior has a number attached to it.